반응형
/*
-- Title : Azure Studio를 활용한 머신러닝 - 2
-- Reference : Datacenter, https://meetup.devopskorea.org/201908-2/
-- Tag : Azure Studio
*/
-- Title : Azure Studio를 활용한 머신러닝 - 2
-- Reference : Datacenter, https://meetup.devopskorea.org/201908-2/
-- Tag : Azure Studio
*/

데이터 전처리도 그래픽컬한 환경에서 처리 할 수 있습니다.
https://studio.azureml.net 접속하여 MS 계정으로 로그인 하고 플라스크 모양 아이콘을 누릅니다.
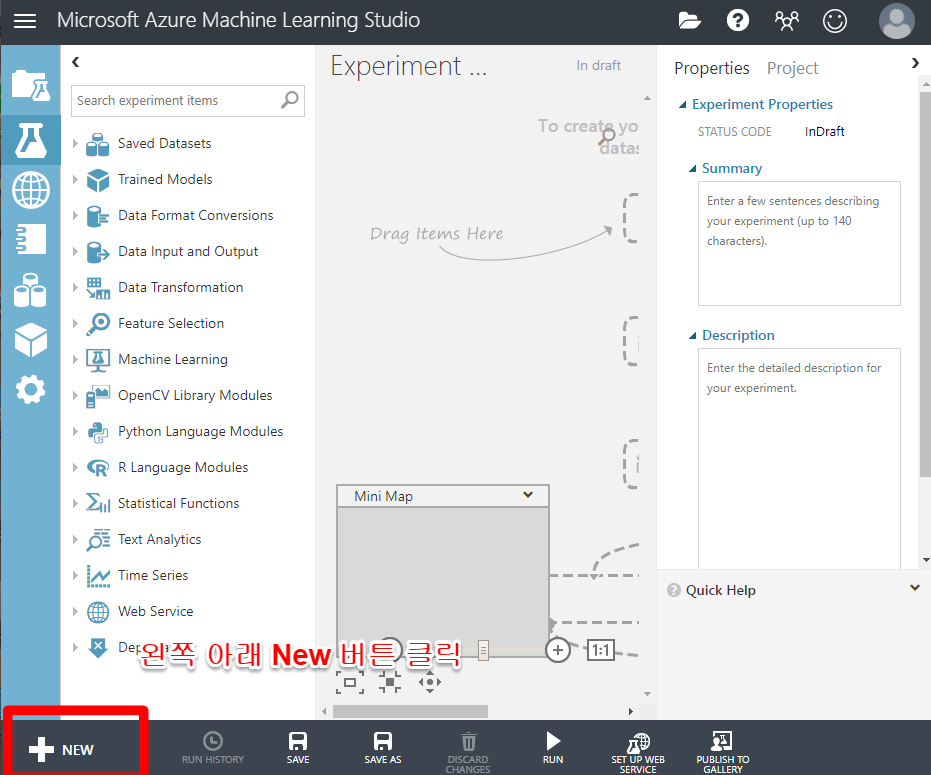
New 버튼을 눌러 분석할 데이터 파일을 업로드합니다.
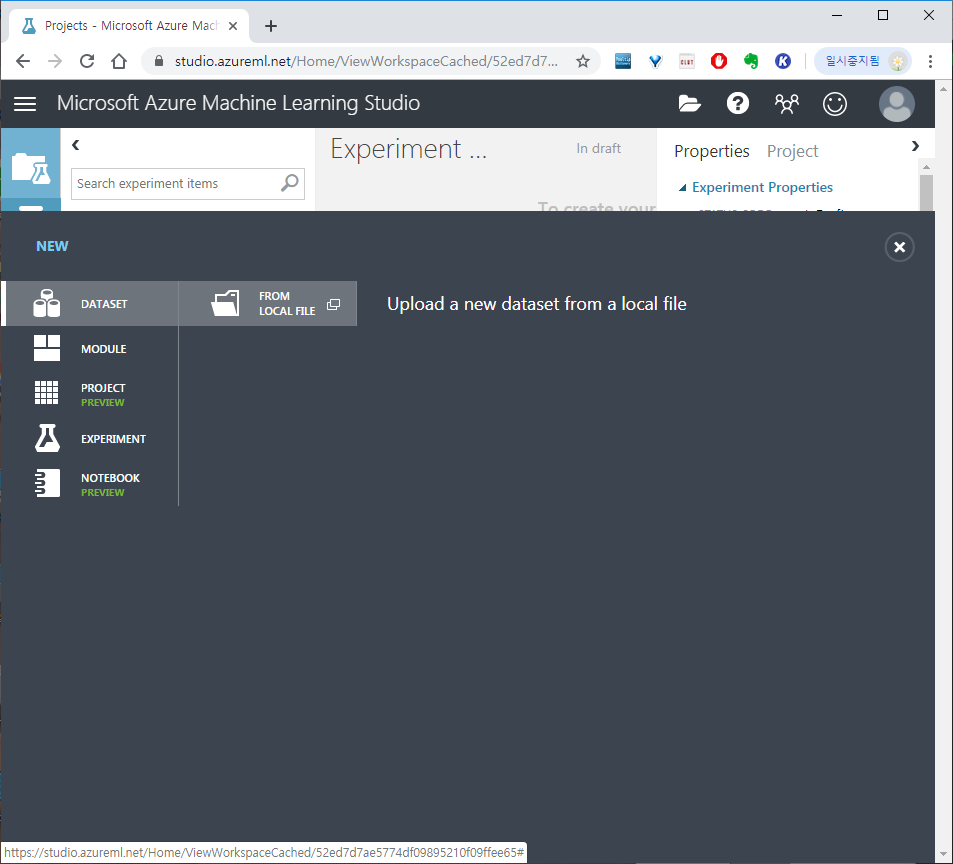
DATASET > FROM LOCAL FILE > 파일 선택하여 학습 파일들을 업로드합니다.
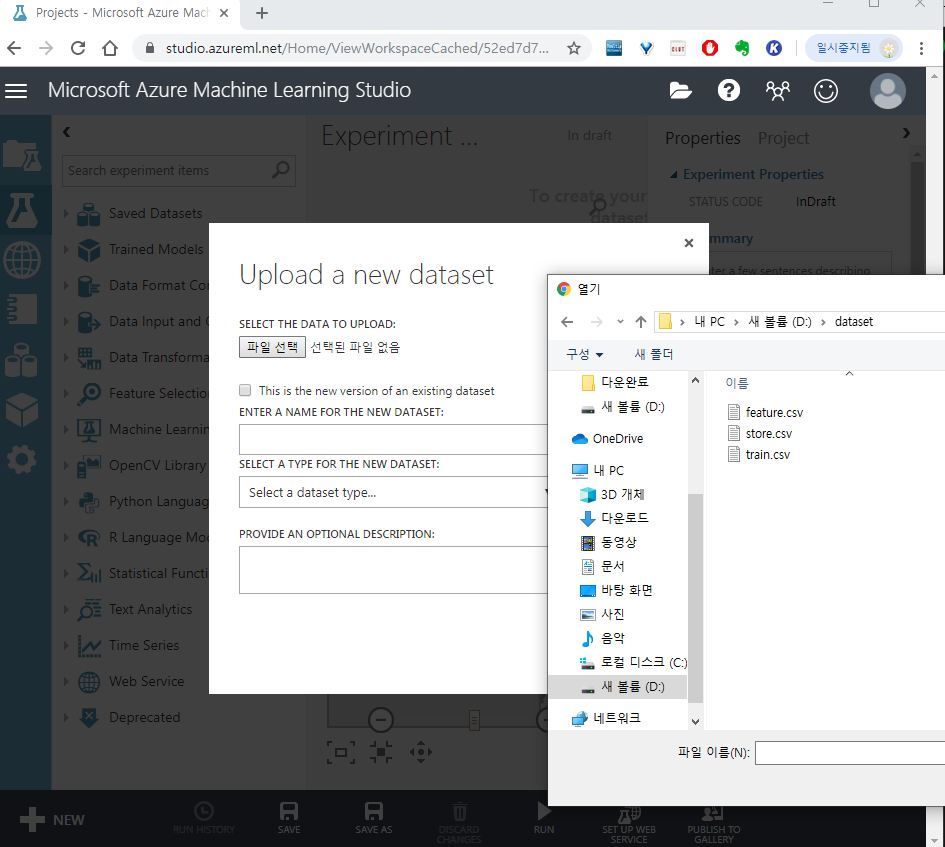
(한번에 하나씩만 가능함)
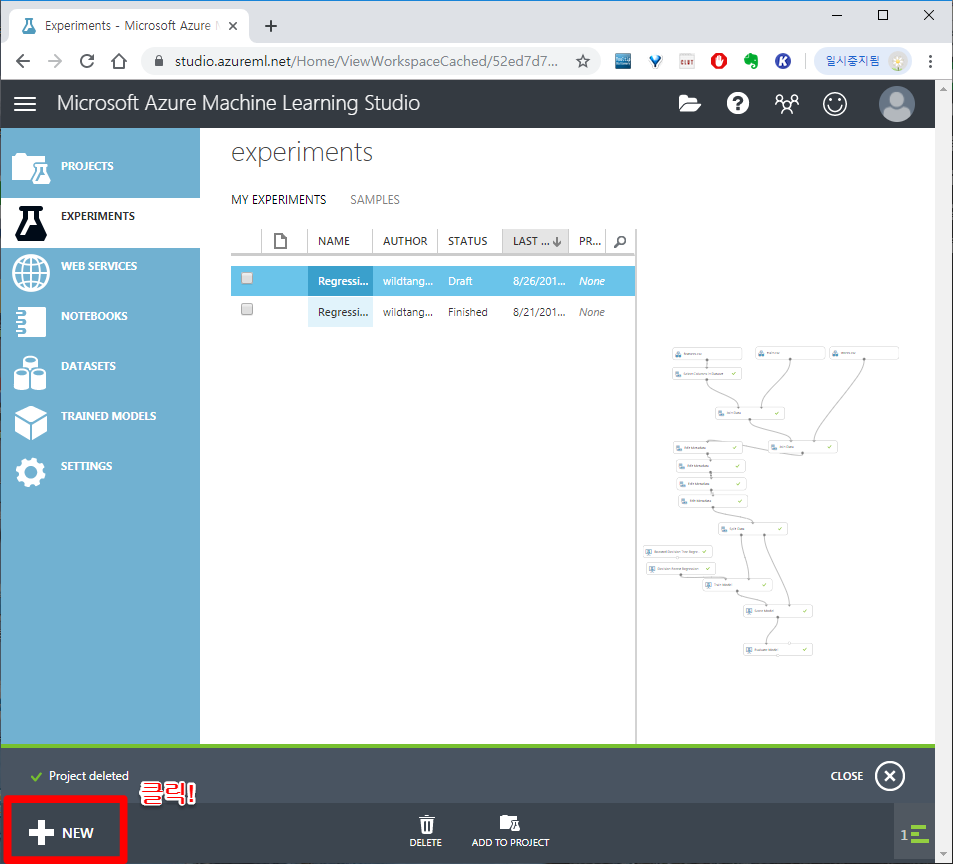
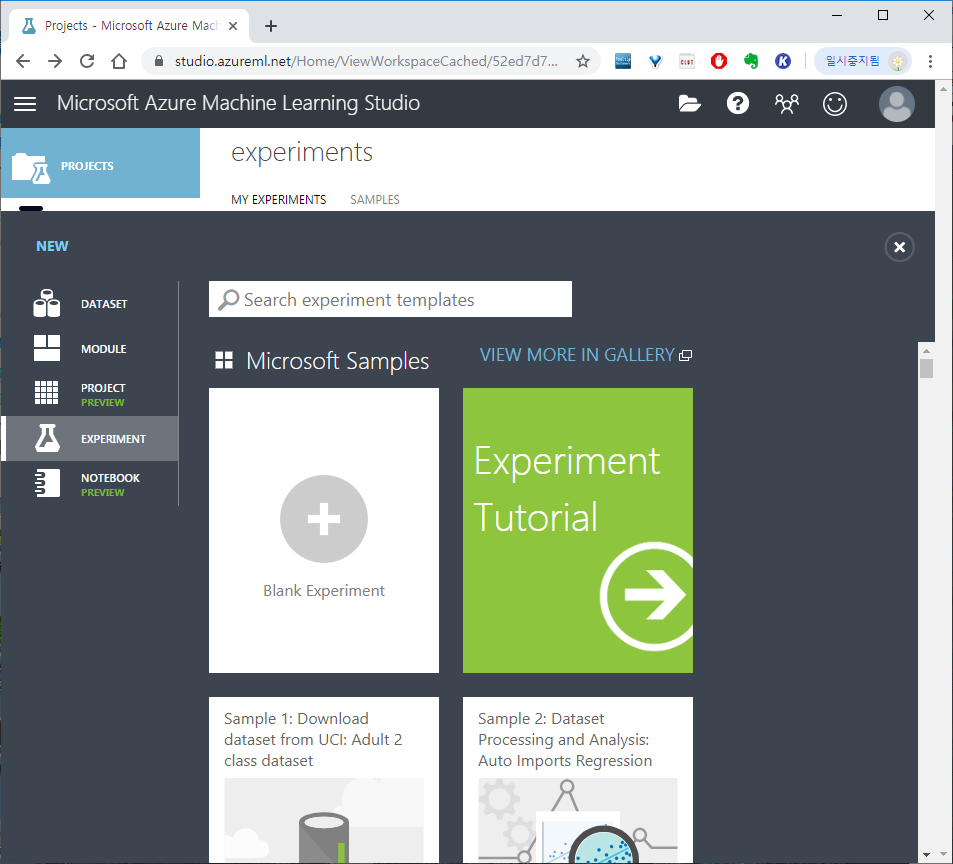
Blank Experiment 클릭하여 새로운 실험 환경(워크스페이스)를 만들었습니다.
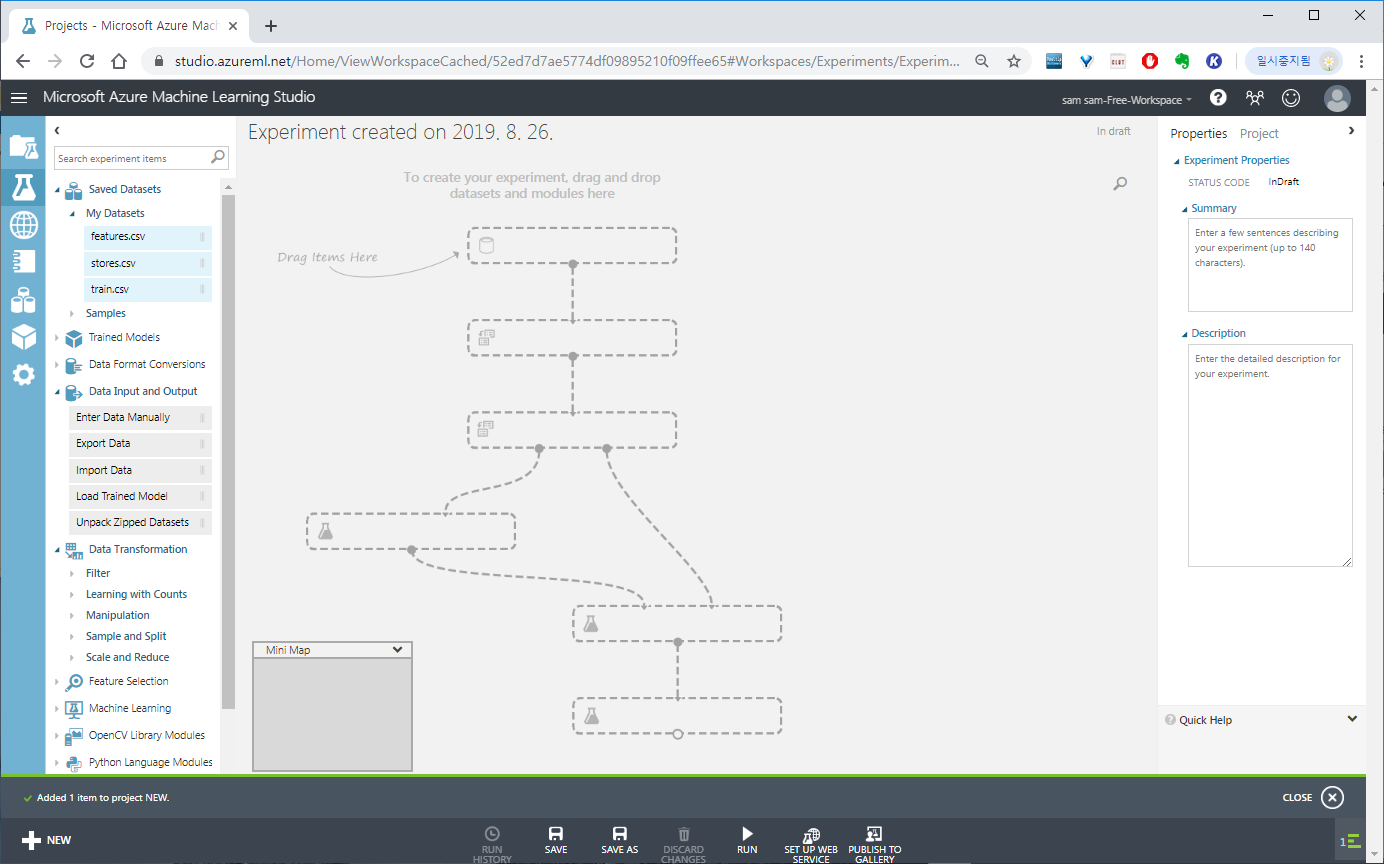
왼쪽 삼각플라스크 모양을 눌렀을 때 나오는 UI입니다.
블럭들을 드래그 엔 드랍으로 올려놓고 각각을 선으로 연결시켜 머신러닝 서비스를 만들 수 있습니다.
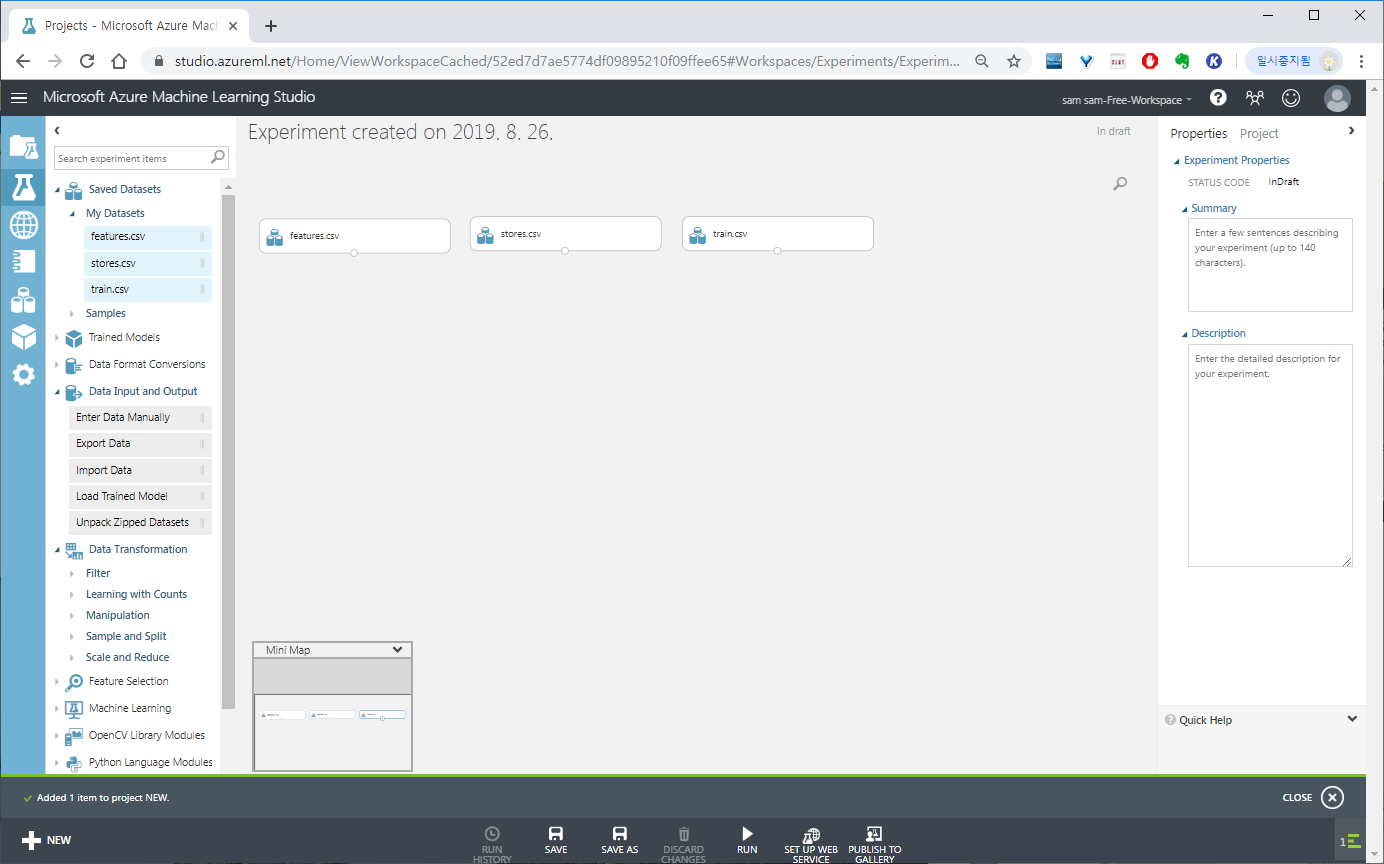
Saved Datasets > My Datasets > 우리가 업로드한 파일들을 화면 하나씩 배치(드래그 앤 드롭)합니다.
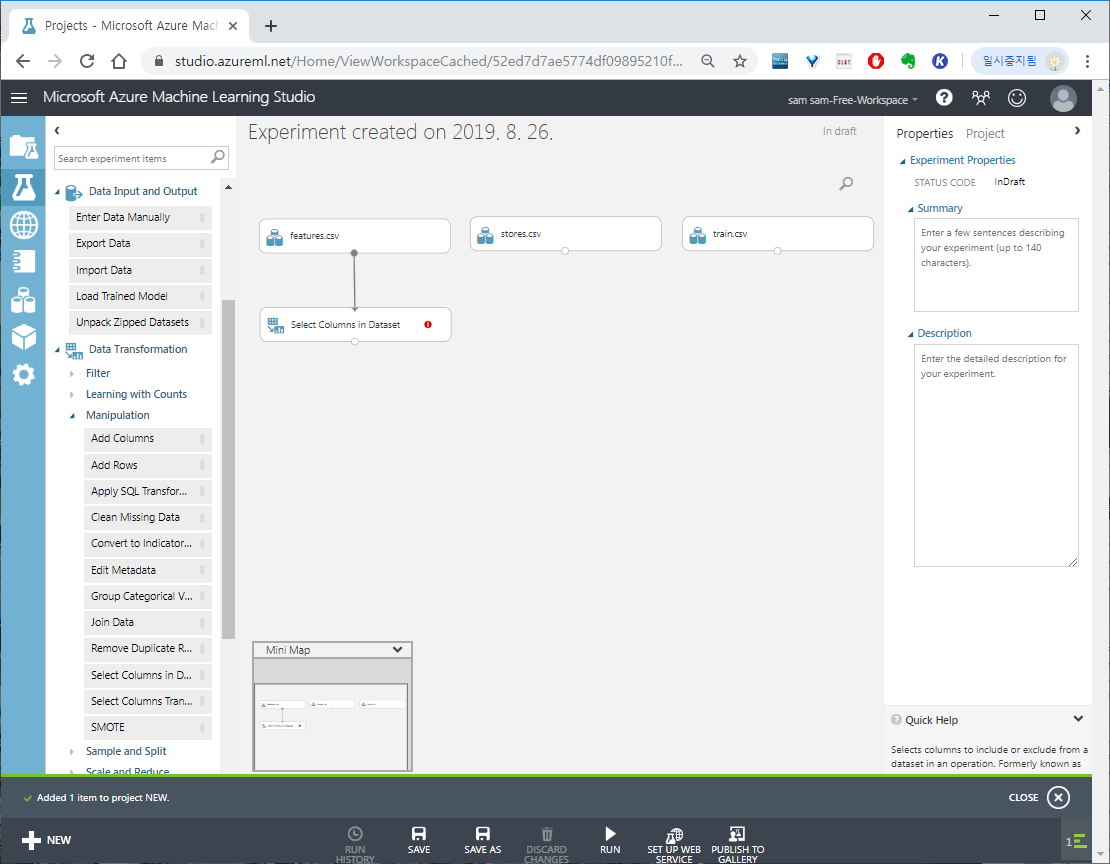
Data Transformation > Select columns in Dataset을 추가하여 선을 연결 시켜줍니다.
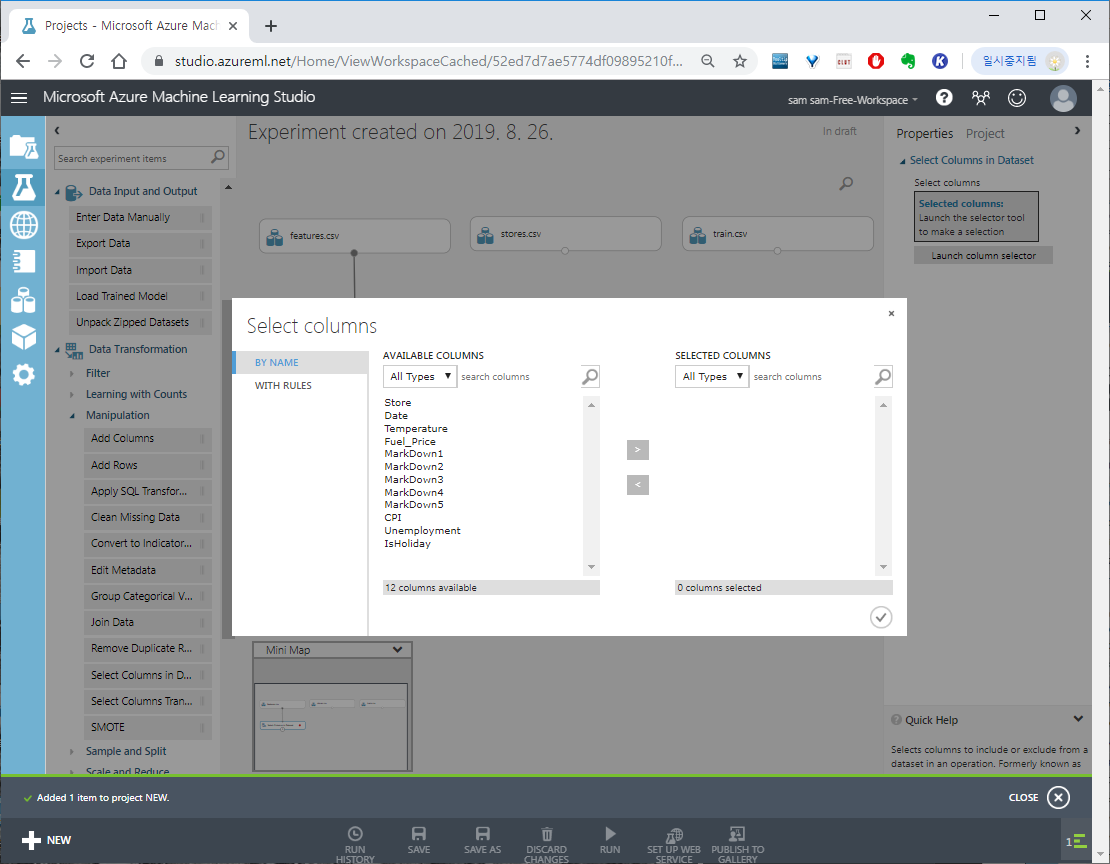
Select columns in Dataset은 이름 그대로 데이터셋에서 필요한 컬럼들을 선택할 수 있습니다.
Select columns in Dataset을 클릭 > 오른쪽 Properties에 Launch colomn selector로 필요한 컬럼들을 선택합니다
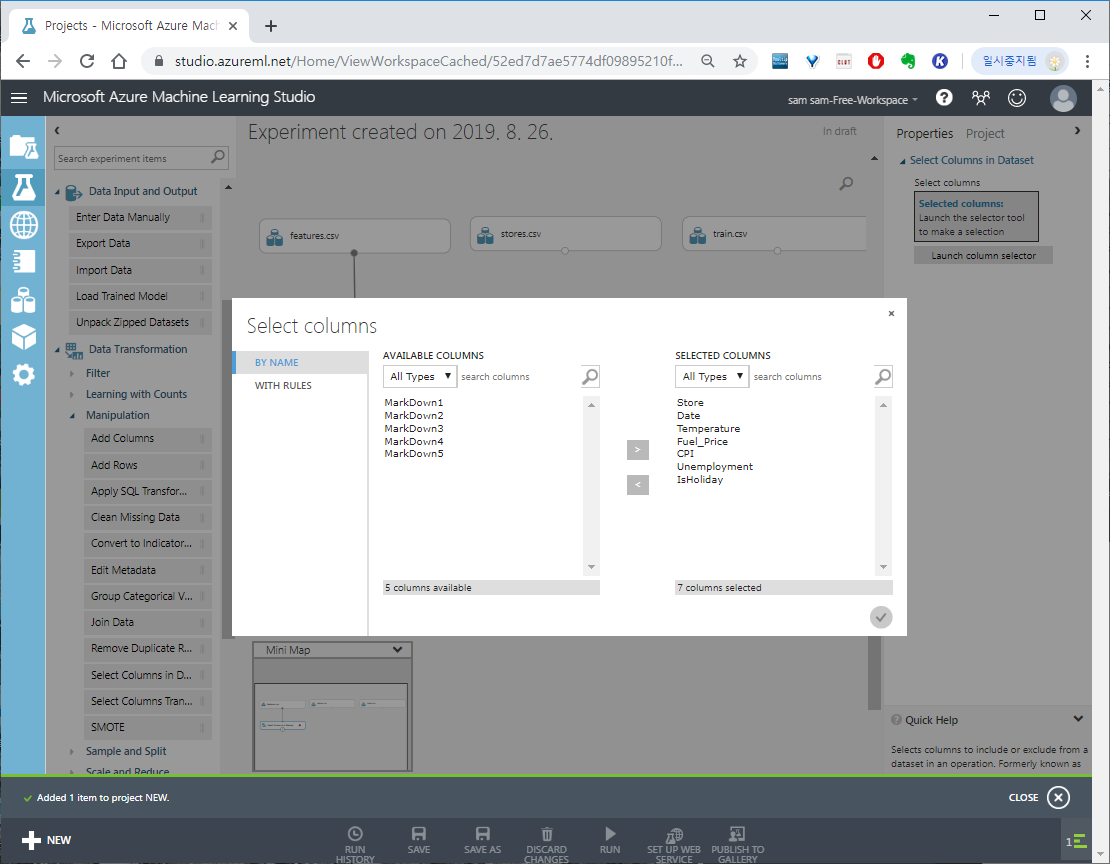
필요한 필드만 선택하여 V를 눌럭 확인합니다.
우리가 가진 데이터셋의 특징입니다. 다른 데이터셋에 비해 준수하지만 사용하기 좋게 다시 한번 전처리 해야합니다.
3개의 파일을 지점,날짜로 조인하고 데이터 형식등 피처이름, 레이블 컬럼등을 지정하는 작업을 이어서 합니다.
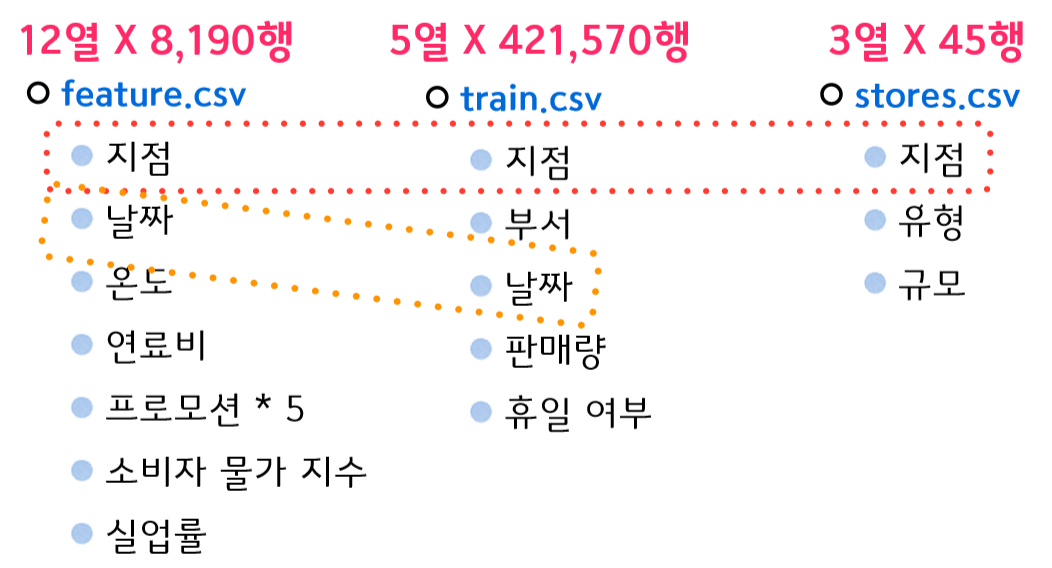
3개의 데이터셋은 Join할 수 있는 컬럼(피처)을 갖고 있습니다.
Feature.csv , train.csv는 `지점`과 `날짜`,
stores.csv는 `지점`으로 조인해 줍니다.
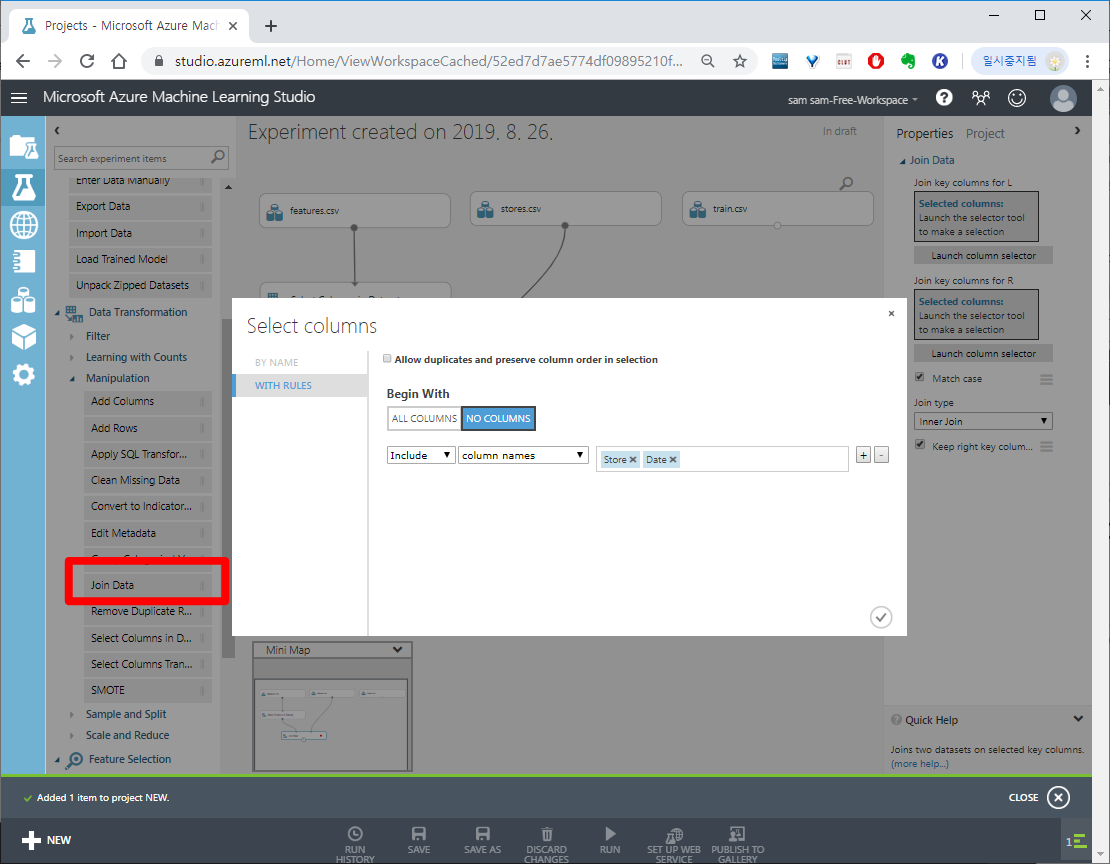
Data Transformation > Join Data 를 끌어다 놓고 왼쪽,오른쪽 input에 조인할 컬럼들(Store,Date)를 입력합니다.
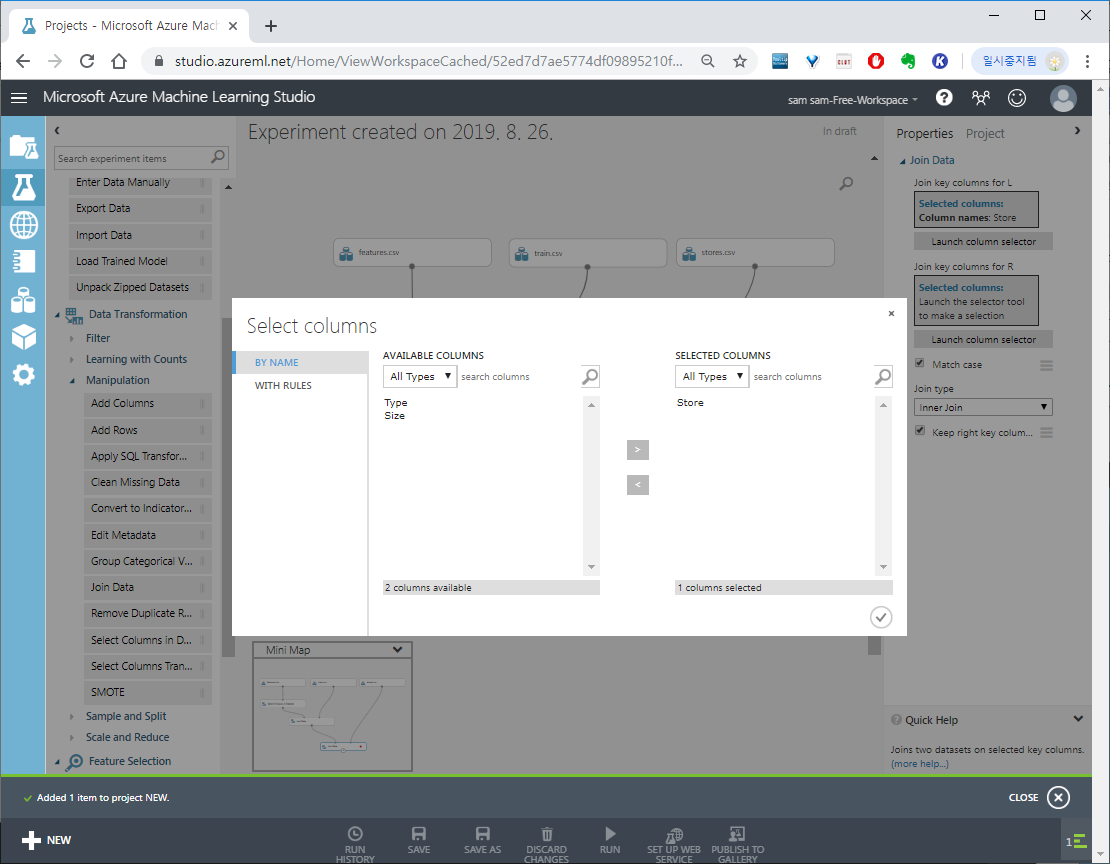
stores.csv는 Store로 조인합니다.
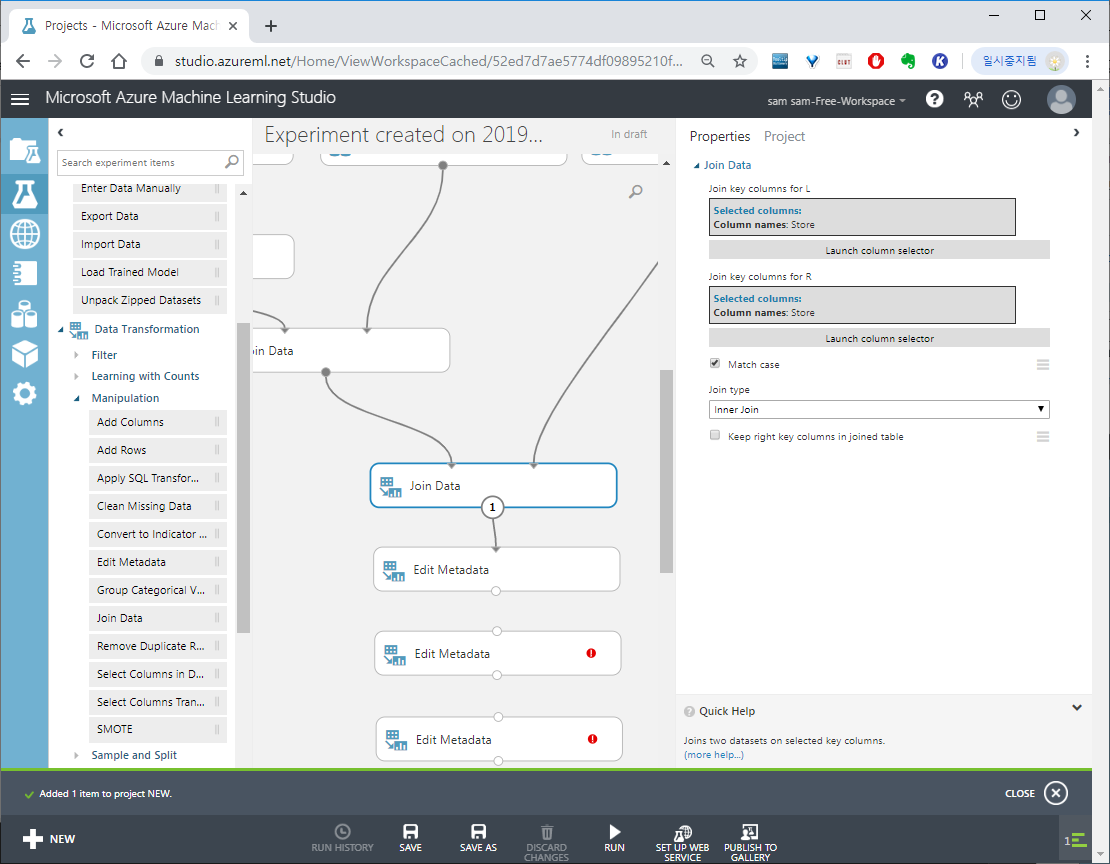
위 사진 오른쪽 중간에 Keep right key columns in joined table 체크박스는 조인한 컬럼의 중복을 놔두겠냐는 물음 입니다 Uncheck 합니다.
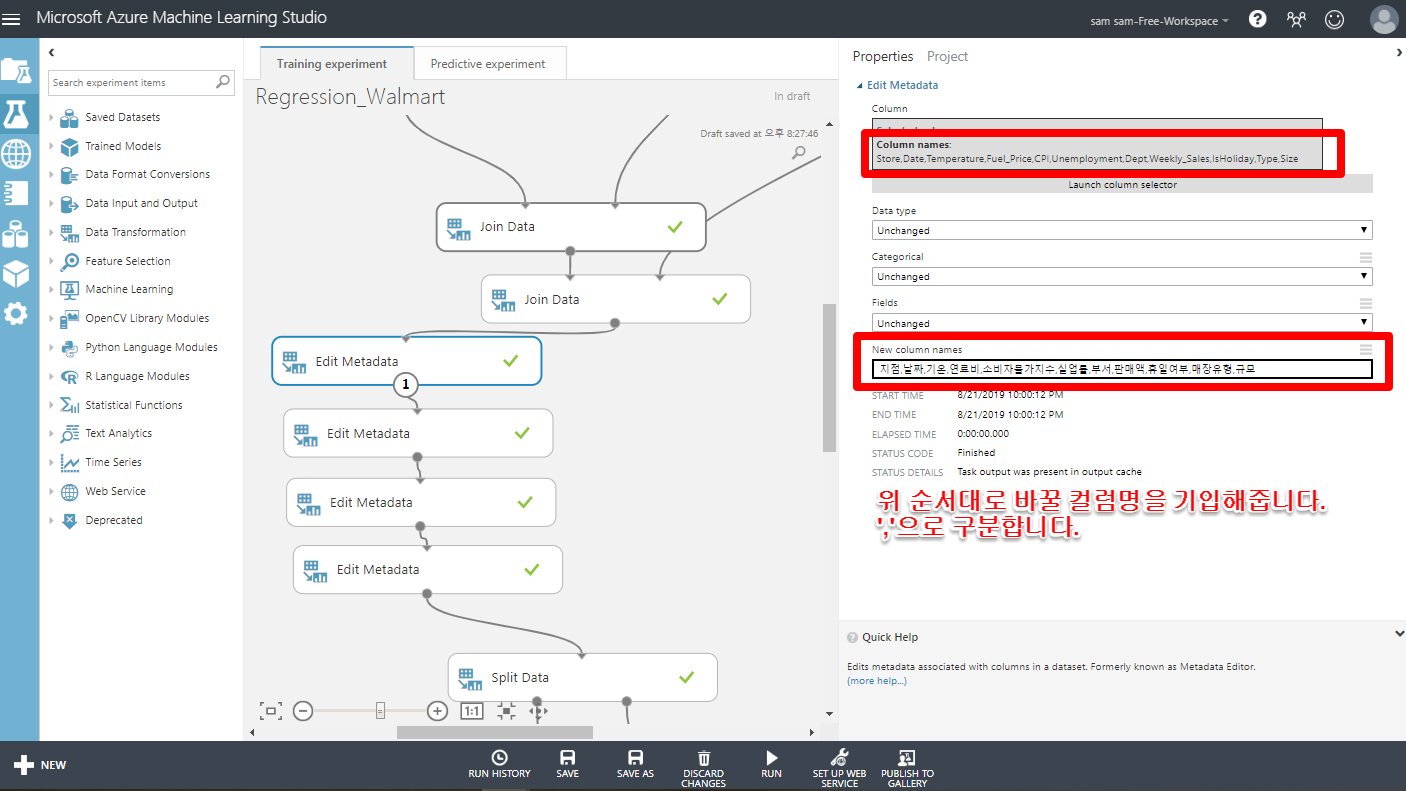
Data Transformation > Manipulation > Edit Metadata
메타 데이터를 편집합니다. 컬럼명을 한글로 바꿉니다.
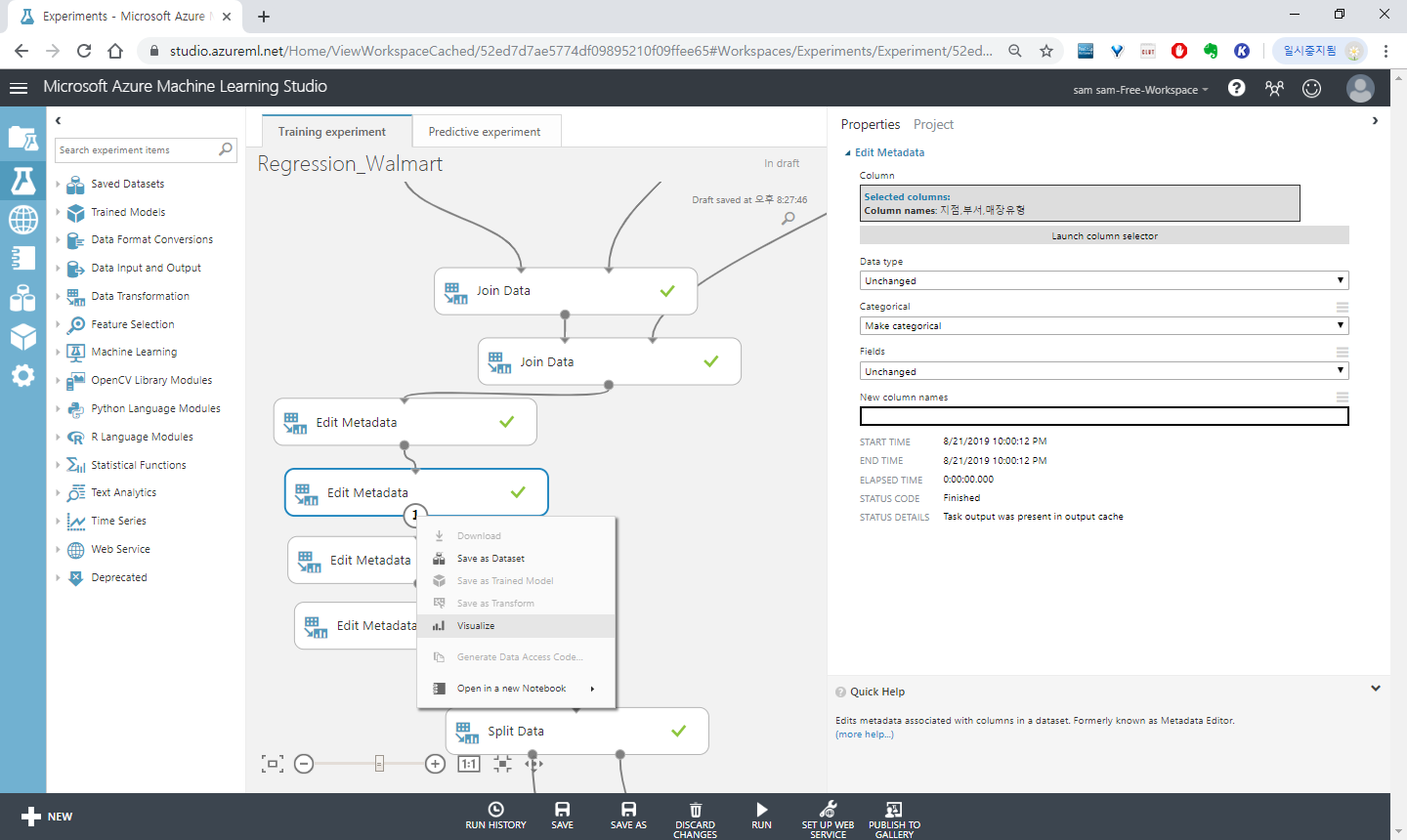
아래 꼭지를 누르면 메뉴에 Visualize 가 있습니다 클릭하여 변경사항을 확인할 수 있습니다. top 100 개의 행을 보여줍니다.
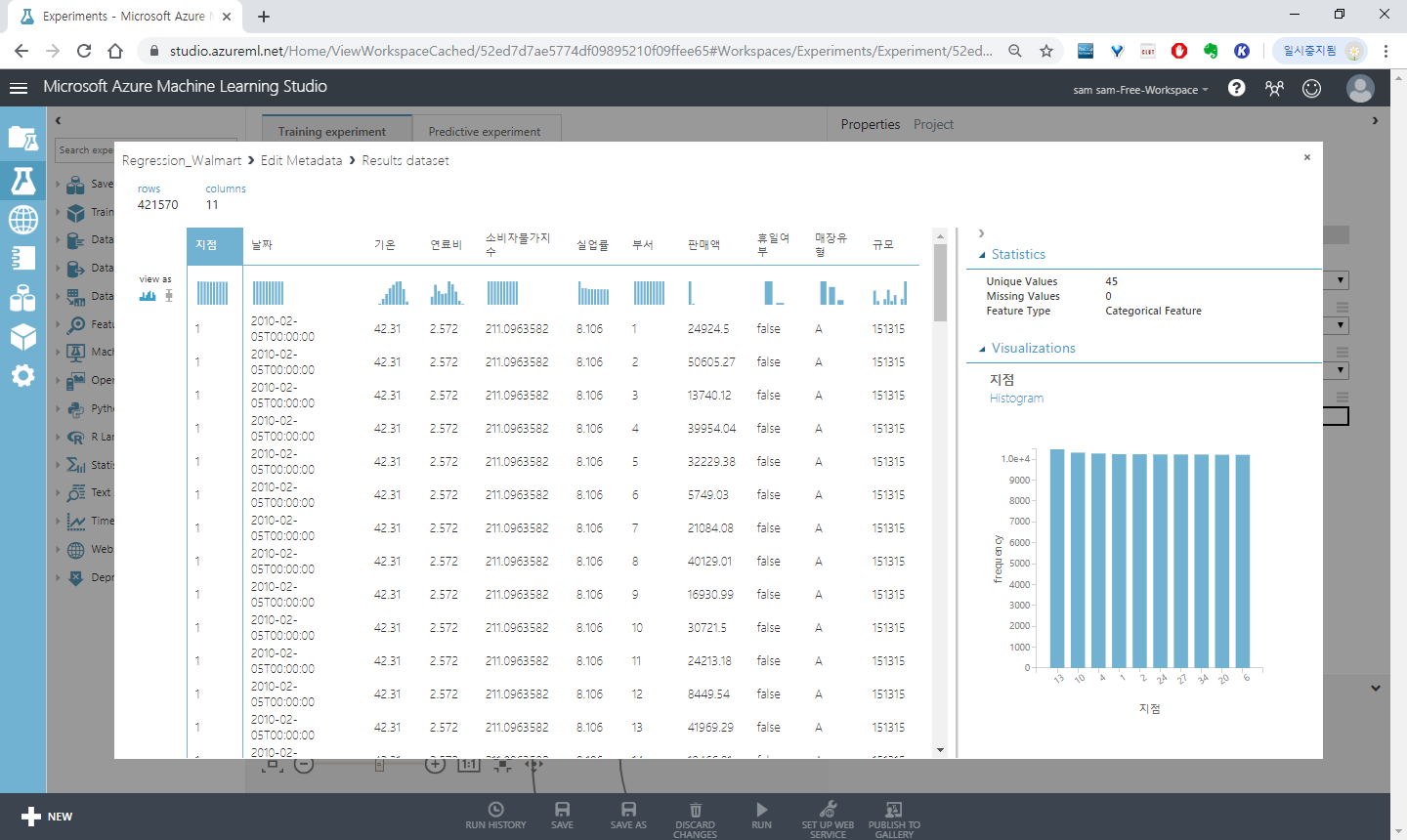
지점, 부서, 매장명을 카테고리컬 피터로 바꿉니다 이 피쳐들은 입력값이 정해져있는 카테고리속성 데이터 입니다
데이터의 오기입을 막고 연산비용을 줄여 줍니다.
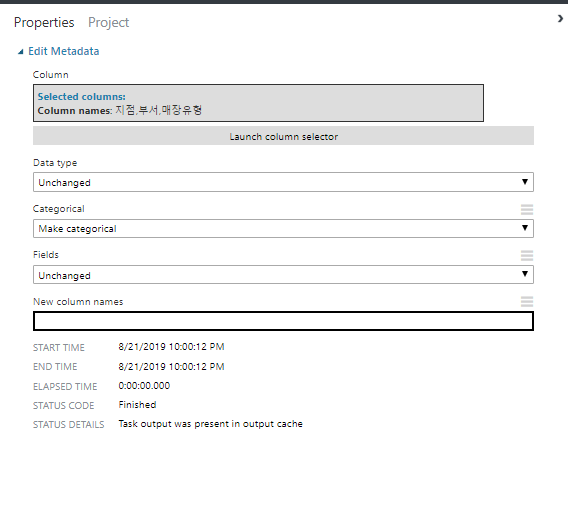
Launch column selector에서 컬럼을 지정하고 Categorical 항목에서 Make categorical을 선택합니다.
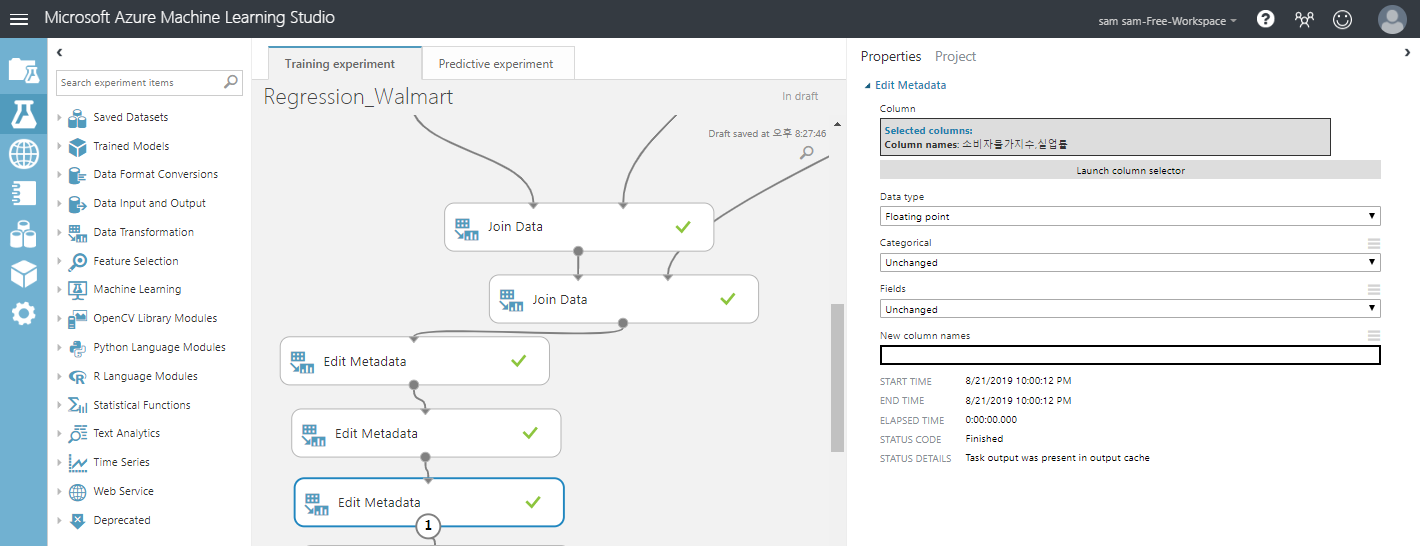
같은 방식으로 소비자 불가지수와 실업률 데이터를 string 형이 아닌 floating point 형으로 바꾸어줍니다.
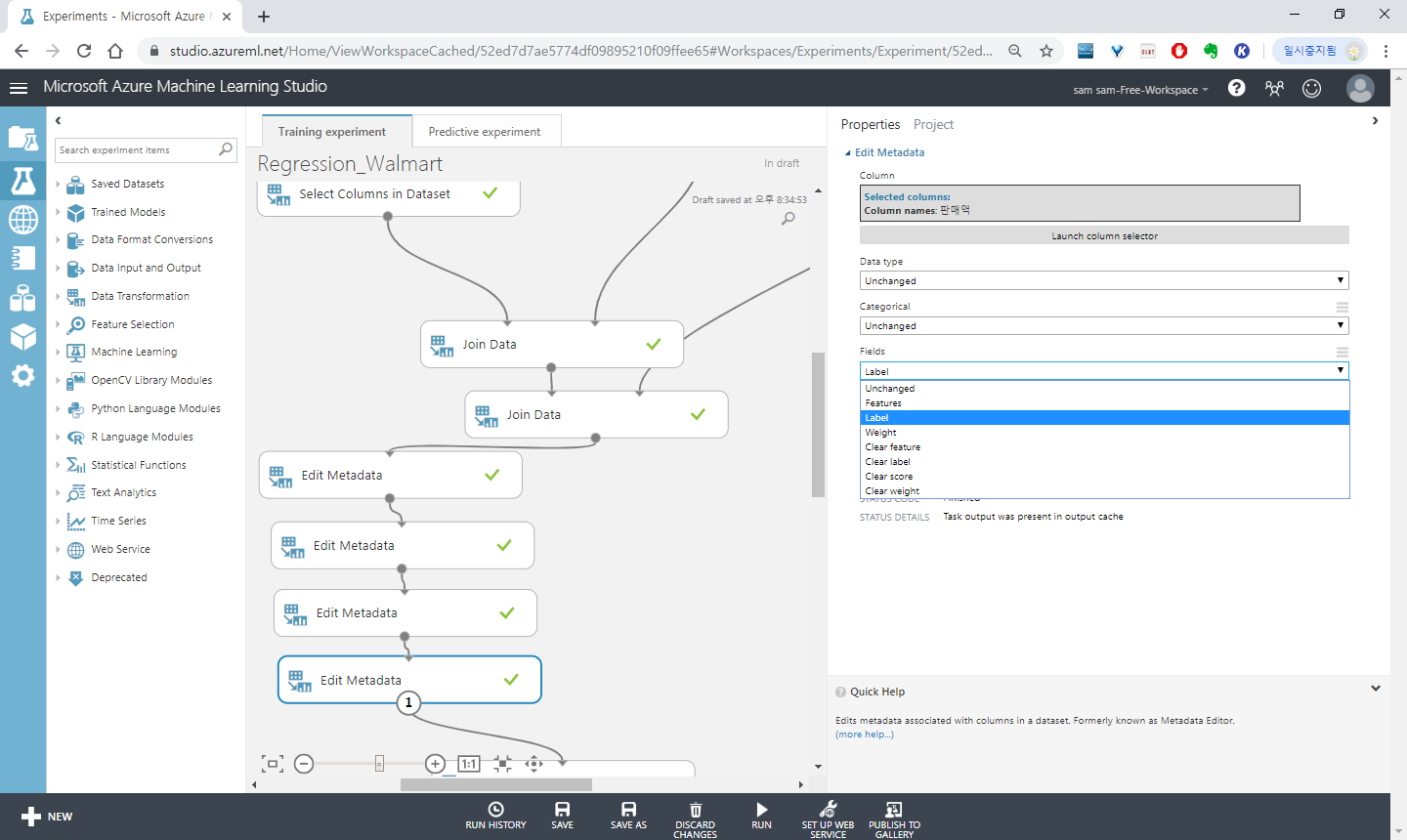
판매액 컬럼을 선택하여 Lable이라고 알려줍니다.
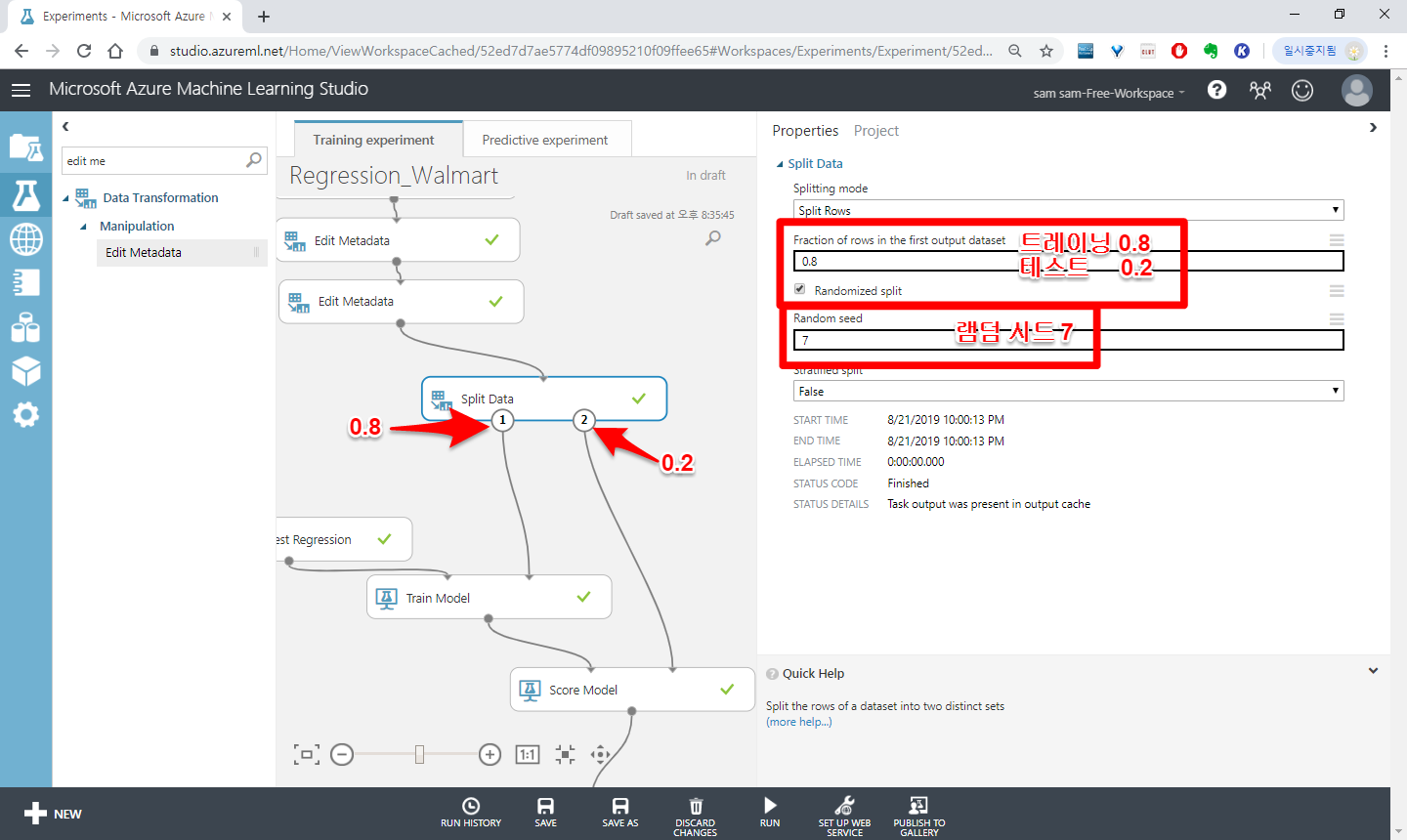
Fraction of rows in the first output dataset 은 트레닝셋과 테스트셋을 나누는 비율이고
Random seed 는 램던하게 데이터를 섞을때 쓰이는데 램덤하게 섞이지만 같은 숫자를 넣으면 램덤하게 섞인 결과가 같습니다.
(0은 Random seed를 사용하지 않음)
반응형