
반응형
/*
-- Title : [DBeaver] PostgreSQL 연결 구성
*/
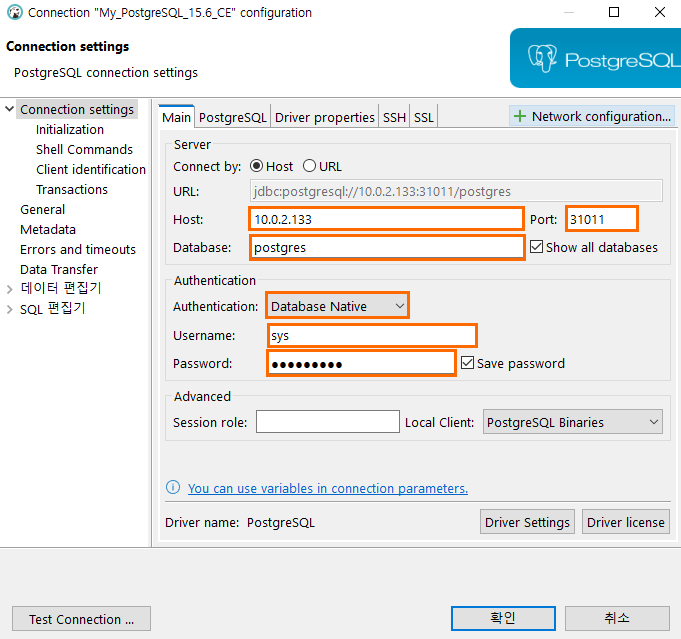
■ PostgreSQL 연결 구성
- pg_hba.conf 추가

- 가상 환경(NAT 네트워크의 포트 포워딩 환경)에서 HOST 주소 추가
- Port는 포트 포워딩에서 정의한 포트 사용
- SUPERUSER 계정 "sys" 생성 후 연결
"CREATE USER sys LOGIN PASSWORD '<비밀번호>' SUPERUSER;" - Database는 기본 시스템DB 'postgres' 지정
반응형